
AI và Dữ Liệu: Quyền Lực Thuật Toán Trong Kỷ Nguyên Hậu Sự Thật
Có một nghịch lý kỳ lạ của thời đại: giữa cơn lũ dữ liệu, điều khan hiếm nhất lại là sự định hướng minh triết. Khi mọi hành vi, cảm xúc, lựa chọn cá nhân đều có thể bị lượng hoá và dự đoán bằng thuật toán, trí tuệ nhân tạo (AI) không còn là một công cụ – mà đã trở thành cấu trúc quyền lực ngầm. Dữ liệu, vốn từng là nguyên liệu của tri thức, nay đang bị tái định nghĩa thành vũ khí chi phối con người: từ thị hiếu tiêu dùng đến niềm tin chính trị, từ thói quen thường nhật đến cả ảo tưởng về bản thân.
Ở giữa ngã ba của tiến bộ và lệ thuộc, Việt Nam đang đối diện với một câu hỏi đặc biệt quan trọng mang tính lịch sử: Chúng ta sẽ là người kiến tạo một tầm nhìn AI mang bản sắc riêng – hay tiếp tục đi theo mô hình số hóa do người khác viết kịch bản?
Bài viết này không chỉ bóc tách sự vận hành âm thầm của dữ liệu và thuật toán trong đời sống hiện đại, mà còn đề xuất một tư duy chiến lược, đạo đức và chủ quyền mới – để Việt Nam không trễ chuyến tàu lịch sử của kỷ nguyên AI.
⚡ Key Takeaways
- AI không còn là công nghệ đơn thuần, mà là hạ tầng quyền lực, chi phối cách con người sống, nghĩ và cảm nhận.
- Dữ liệu đang thay thế ngôn ngữ và văn bản trong việc định hình tư tưởng – biến thuật toán thành người kể chuyện lớn nhất thời đại.
- Thuật toán không trung lập – nó mang định kiến, mục tiêu và tham vọng của người tạo ra nó.
- Việt Nam cần một chiến lược chủ quyền dữ liệu để không bị chi phối hoàn toàn bởi các nền tảng ngoại quốc.
- Tư duy về AI và dữ liệu không thể chỉ gói gọn trong phạm trù công nghệ – mà phải là cuộc thảo luận toàn xã hội, từ chính sách đến giáo dục, từ đạo đức đến văn hóa.
I. AI và Dữ liệu – Từ Công Cụ Thành Cấu Trúc Quyền Lực
1.1. Tại sao AI không còn là công cụ trung lập?
Trong phần lớn thế kỷ 20, con người phát triển công nghệ như một công cụ phụ trợ: từ máy tính để bàn, bộ xử lý văn bản cho đến điện thoại di động. Nhưng đến giữa thập niên 2020, một bước ngoặt đã diễn ra âm thầm mà mang tính bản lề: AI không còn là một công cụ thuần tuý để xử lý thông tin, mà dần trở thành một tầng lớp “có quyền lực” quyết định sự thật nào được hiển thị, nội dung nào được lan truyền, cảm xúc nào được củng cố.
Trí tuệ nhân tạo không chỉ tính toán – nó gợi ý, định hướng, tạo nội dung mới, và đôi khi tự ra quyết định dựa trên tập huấn luyện vốn đầy thiên kiến xã hội và yếu tố lịch sử. Khi người dùng gõ một câu hỏi vào ChatGPT hay dùng giọng nói trò chuyện với trợ lý ảo, họ không đơn thuần nhận câu trả lời khách quan – họ đang tương tác với một cơ chế định hình nhận thức được lập trình bởi một tập đoàn với lợi ích riêng biệt.
Một xã hội nơi mọi lĩnh vực – giáo dục, y tế, truyền thông, kinh tế – đều có sự tham gia của AI, chính là một AI-centric society (xã hội lấy AI làm trung tâm). Trong xã hội đó, người ta không còn nhận biết được khi nào mình đang “tiêu dùng AI,” vì AI đã trở thành không khí, ẩn trong mỗi cú lướt điện thoại, mỗi dòng chữ trên nền tảng mạng xã hội, mỗi bản nhạc phát ngẫu nhiên.
“AI là công cụ duy nhất trong lịch sử mà khi bạn sử dụng, nó cũng đang sử dụng lại bạn.” – lời cảnh báo của nhà lý thuyết công nghệ Jaron Lanier không còn là viễn tưởng.
1.2. Dữ liệu – nguyên liệu quyền lực của thế kỷ 21
Trong thế giới hiện đại, dữ liệu không còn là thông tin rời rạc – nó là tài nguyên chiến lược, ngang hàng với dầu mỏ, đất hiếm, và tri thức. Khác với tri thức được chắt lọc qua kinh nghiệm và quán trình phản tư, dữ liệu là hình ảnh tức thời của hành vi người dùng, được thu thập liên tục và vô hình.
Từ dữ liệu tìm kiếm, vị trí, giấc ngủ, đến nhịp tim và giọng nói – con người hiện đại không còn giữ sự riêng tư như một mặc định, mà sống trong một mô hình gọi là “tự giám sát mềm”: nơi mọi hành vi đều có thể bị mã hoá, phân tích và thương mại hoá.
Các tập đoàn lớn như Google, Meta, Amazon, Alibaba… đã trở thành những “đế chế dữ liệu,” nơi quyền lực không nằm ở vũ khí, mà nằm ở năng lực dự đoán và định hình hành vi. Dữ liệu của bạn không chỉ được dùng để bán sản phẩm, mà còn để huấn luyện AI – vốn sẽ tiếp tục thay thế bạn trong chính ngành nghề của bạn.
Đây không còn là câu chuyện kỹ thuật – mà là một cuộc cạnh tranh chiến lược ở tầm quốc gia. Những ai kiểm soát được dòng chảy dữ liệu – sẽ kiểm soát được nền kinh tế, truyền thông, và cả ý thức xã hội.
II. Quyền lực thuật toán – Ẩn nhưng chi phối mọi thứ
2.1. Khi thuật toán quyết định ai được nhìn thấy – ai bị loại bỏ
Mỗi ngày, hàng tỷ người mở điện thoại để đọc tin tức, xem video, lướt mạng xã hội. Họ tưởng rằng mình “chọn” xem thứ mình thích. Nhưng thực tế, thuật toán đã chọn trước cho họ.
Từ YouTube, TikTok, Facebook cho đến Netflix – các hệ thống đề xuất (recommendation engines) hoạt động không phải để cung cấp thông tin khách quan, mà để tối ưu thời gian ở lại, tăng khả năng tương tác, và tối đa hóa lợi nhuận quảng cáo. Nội dung bạn thấy không phải ngẫu nhiên – mà là kết quả của một chuỗi mô hình thống kê, sắp xếp dựa trên hồ sơ hành vi của chính bạn.

Câu hỏi đặt ra: ai viết thuật toán? Ai xác định giá trị nào được ưu tiên hiển thị? Những người kiểm soát thuật toán – chính là những biên tập viên vô hình của kỷ nguyên số. Nhưng khác với báo chí truyền thống, họ không chịu trách nhiệm trước công luận – mà chỉ trả lời trước hội đồng cổ đông.
Ở cấp độ xã hội, điều này tạo ra một hiệu ứng nguy hiểm: người ta chỉ thấy thứ họ đã từng thích, và dần rơi vào buồng cộng hưởng thông tin (echo chamber). Những góc nhìn trái chiều, quan điểm thiểu số, tiếng nói phản biện – đều bị đẩy ra ngoài biên của luồng dữ liệu chính.
2.2. Hậu sự thật: Khi cảm xúc được thiết kế bằng dữ liệu
Chào mừng đến với thời đại hậu sự thật (post-truth) – nơi cảm xúc quan trọng hơn sự thật, và niềm tin được thiết kế có chủ đích.
Trong kỷ nguyên này, các thuật toán không còn đơn thuần sắp xếp thông tin – mà định hình cảm xúc tập thể. Một video “cảm động,” một dòng tweet phẫn nộ, một tấm hình gây chia rẽ… tất cả được tối ưu để lan truyền – không phải vì đúng, mà vì có khả năng kích thích phản ứng mạnh mẽ nhất.
Điều đáng sợ là: những cảm xúc này không xuất phát từ nội tâm người dùng – mà được khuấy động bởi các phép tính xác suất. Khi bạn tức giận vì một đoạn clip, khi bạn bật khóc vì một tin giả, khi bạn share một nội dung gây sốc… bạn đang phản ứng với một hệ sinh thái được tối ưu để khai thác tâm lý bạn.
“Chúng ta không còn sống trong một nền dân chủ thông tin – mà đang trượt vào một chế độ cảm xúc được định dạng bằng thuật toán.”
Các hệ thống AI học từ hành vi xã hội không để phục vụ sự thật – mà để tối ưu kết quả. Và kết quả ở đây không phải là kiến thức – mà là sự kích thích cảm xúc, khả năng thao túng, và hành vi tiêu dùng.
Trong kịch bản này, dữ liệu không chỉ là công cụ – mà là vũ khí. Và AI không chỉ học – nó lập trình lại cả xã hội.

III. Đạo đức AI và rủi ro từ sự thiếu kiểm soát
3.1. Ba vụ bê bối vạch trần mặt tối của AI và dữ liệu: Những bài học chưa kịp rút ra
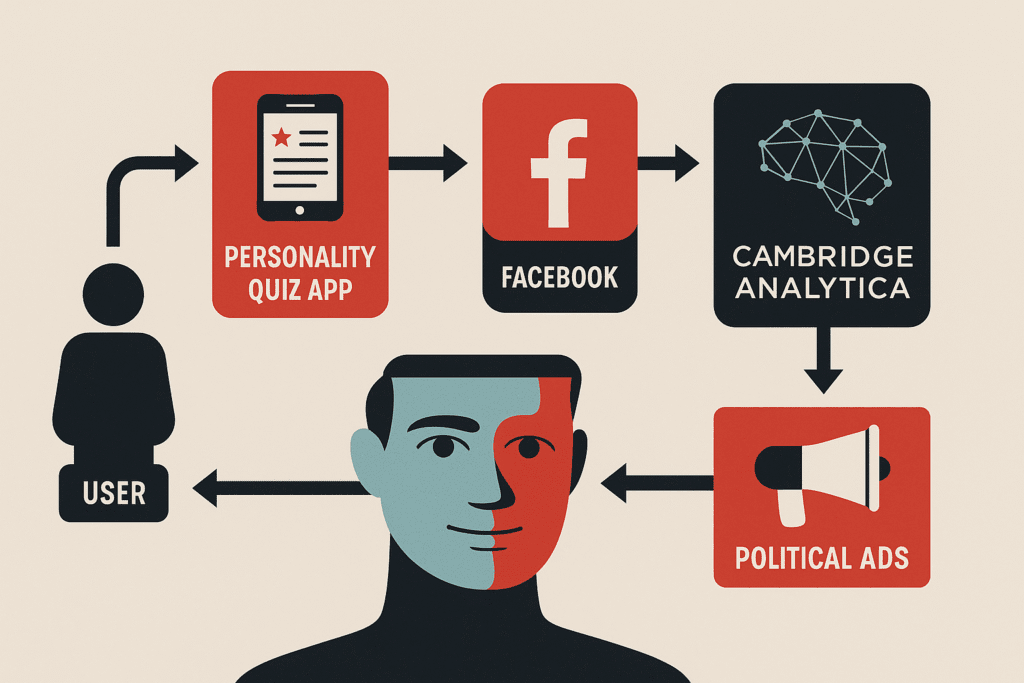
🧩 Case 1 – Cambridge Analytica: Khi dữ liệu trở thành vũ khí thao túng Nền dân chủ
Bối cảnh:
Năm 2018, scandal nổ ra khi công ty phân tích dữ liệu chính trị Cambridge Analytica bị phát hiện thu thập dữ liệu Facebook trái phép từ hơn 87 triệu người dùng thông qua một ứng dụng trắc nghiệm tâm lý. Những người dùng tham gia khảo sát (chỉ vài trăm nghìn) đã vô tình mở quyền truy cập danh bạ bạn bè – khiến dữ liệu lan rộng ra hàng chục triệu tài khoản.
Cơ chế thao túng:
Dựa trên dữ liệu thu thập được (giới tính, tuổi, niềm tin chính trị, hành vi tương tác…), Cambridge Analytica xây dựng mô hình hồ sơ tâm lý (psychographic profiling). Họ dùng các mô hình ngôn ngữ (machine learning) để xác định ai dễ bị tác động bởi nội dung tiêu cực, ai dễ bị khơi dậy cảm xúc sợ hãi, ai dễ thay đổi chính kiến.
Sau đó, họ phân phối nội dung quảng cáo chính trị siêu cá nhân hoá (micro-targeted ads) cho từng nhóm cử tri – khiến họ thay đổi hành vi bỏ phiếu mà không hề nhận ra mình đang bị thao túng.
Tác động:
- Ảnh hưởng trực tiếp đến cuộc bầu cử Tổng thống Mỹ 2016, Brexit, và nhiều chiến dịch chính trị tại Kenya, Mexico, Ấn Độ.
- Facebook bị phạt 5 tỷ USD nhưng không phải chịu trách nhiệm hình sự.
- Dữ liệu cá nhân trở thành tài sản chiến lược – nhưng công dân vẫn không có quyền sở hữu hay kiểm soát thực sự.
Bài học:
AI + dữ liệu hành vi = vũ khí chiến tranh nhận thức (cognitive warfare).
Một khi cảm xúc và định kiến cá nhân có thể bị thao túng bằng thuật toán, nền dân chủ không còn vận hành dựa trên tự do ý chí – mà dựa trên thiết kế tâm lý.
🧩 Case 2 – Deepfake Ukraine: Khi thông tin giả có thể khởi động hoặc kết thúc chiến tranh
Bối cảnh:
Tháng 3/2022, giữa lúc xung đột Nga–Ukraine căng thẳng, một video deepfake lan truyền trên mạng cho thấy Tổng thống Volodymyr Zelensky đứng trước máy quay, kêu gọi binh sĩ Ukraine hạ vũ khí và đầu hàng.
Video được phát tán đồng thời trên Telegram, Facebook và các nền tảng Nga. Tuy chất lượng hình ảnh và giọng nói còn khá thô, nhưng trong một thời điểm khủng hoảng, tác động tâm lý có thể rất lớn – nhất là nếu nó đến trước các kênh kiểm chứng chính thức.
Cơ chế thao túng:
Video được tạo bằng mô hình deepfake GAN (Generative Adversarial Network) – tái dựng gương mặt và giọng nói Zelensky từ hàng ngàn giờ video gốc có sẵn. Từ đó, AI tạo ra một bản dựng có vẻ chân thực, đủ để gây nhiễu thông tin và làm lung lay tinh thần kháng chiến.
Tác động:
- May mắn là chính phủ Ukraine phản ứng nhanh, đưa ra bản gốc và bác bỏ video giả.
- Tuy nhiên, đây là lời cảnh báo: trong thời đại chiến tranh thông tin, sự thật không còn là ranh giới vững chắc.
- Nếu video được tinh chỉnh tốt hơn và phát tán đồng bộ hơn, có thể đã gây ra khủng hoảng niềm tin và gián đoạn chiến lược.
Bài học:
Deepfake không chỉ là công cụ giải trí hay bôi nhọ cá nhân – nó có thể là cú đánh hạ gục niềm tin, phá vỡ lệnh điều binh, và thao túng cục diện chiến tranh.
Trong thời đại AI, nạn nhân không còn là người bị quay – mà là toàn xã hội đang xem.
🧩 Case 3 – AI phân biệt đối xử trong ngành tài chính và hành chính công (Trung Quốc và Mỹ)
Bối cảnh:
Nhiều mô hình AI hiện nay được sử dụng trong hệ thống cho vay tài chính, tuyển dụng nhân sự, đánh giá hồ sơ nhập cư, và thậm chí phân loại công dân (như hệ thống “điểm tín nhiệm xã hội” ở Trung Quốc).
Vấn đề:
Do AI học từ dữ liệu quá khứ – vốn mang nặng thiên kiến xã hội – nên khi triển khai, AI tiếp tục củng cố và nhân rộng các bất công.
- Ở Mỹ: AI đánh giá tín dụng xếp hạng thấp hơn cho người da đen và phụ nữ vì lịch sử tín dụng từng bị phân biệt đối xử.
- Ở Trung Quốc: AI trong hệ thống giám sát công cộng được triển khai để theo dõi người Duy Ngô Nhĩ, gắn nhãn hành vi “đáng ngờ” chỉ dựa trên diện mạo, tôn giáo, khu vực sinh sống.
Tác động:
- AI trở thành công cụ chính thống hoá sự phân biệt mà lẽ ra xã hội cần phải vượt qua.
- Người dân bị từ chối vay vốn, không được phỏng vấn, hoặc bị gắn nhãn an ninh – mà không ai hiểu tại sao.
Bài học:
AI không phải luôn thông minh – mà thường thiếu đạo đức nếu không được kiểm soát.
Công lý thuật toán (algorithmic justice) là khái niệm cấp thiết – nhưng chưa được đưa vào luật ở phần lớn quốc gia đang phát triển, bao gồm Việt Nam.
3.2. Những lỗ hổng đạo đức chưa có lời giải
Các vụ bê bối nói trên chỉ là phần nổi của tảng băng chìm. Phía dưới là một thực tế phức tạp và chưa có lời giải: AI không “tốt” cũng không “xấu” – nó chỉ trung thành với mục tiêu người tạo ra lập trình sẵn. Và trong một thế giới mà mục tiêu tối thượng thường là tối ưu lợi nhuận, tương tác và tốc độ… thì đạo đức trở thành thứ đứng ngoài vòng ưu tiên.
❖ Vấn đề 1: AI học từ thế giới lệch lạc – rồi phản ánh lại sự lệch lạc ấy như thể là sự thật
Tưởng tượng một AI được huấn luyện để tự động xét hồ sơ tuyển dụng. Nếu dữ liệu đầu vào là lịch sử tuyển dụng từ một công ty từng thiên vị đàn ông, từng gạt ra những ứng viên có tên gốc Phi, hoặc từng ưu tiên ứng cử viên tốt nghiệp từ một vài trường đại học nhất định… thì AI không “phân biệt đối xử” theo ý thức – mà nó học từ chính bất công lịch sử. Kết quả là gì? Bất công được tự động hóa.
Khi AI đưa ra quyết định loại ai, giữ ai – mà không thể giải thích được vì sao, ta đang đối diện với cái gọi là “hộp đen thuật toán”. Sự vô minh này không chỉ khiến con người mất quyền kiểm tra – mà còn khiến niềm tin xã hội vào hệ thống công nghệ bị xói mòn.
Điều nguy hiểm không nằm ở chỗ AI sai – mà ở chỗ nó sai một cách có hệ thống, trong im lặng, và không thể phản biện.
❖ Vấn đề 2: Trách nhiệm mờ nhòe – ai chịu trách nhiệm khi AI sai?
Giả sử một xe tự lái gây tai nạn chết người. Ai phải chịu trách nhiệm? Người ngồi sau vô lăng? Công ty phần mềm? Người dạy dữ liệu? Kỹ sư thiết kế hệ thống? Hay… không ai cả?
Trong thế giới hiện tại, khung pháp lý về trách nhiệm AI gần như trống rỗng. Các công ty có thể tuyên bố rằng “đây chỉ là công cụ hỗ trợ”, còn người dùng lại không đủ tri thức để phản biện.
Tình trạng này tạo ra một vùng xám nguy hiểm về pháp lý và đạo đức, nơi sự tổn hại diễn ra mà không có người gánh chịu. AI, vốn không có đạo đức, được sinh ra trong môi trường cũng thiếu đạo đức – thì hệ quả là gì, nếu không phải là mất kiểm soát?
❖ Vấn đề 3: Các quốc gia đang phát triển – bao gồm Việt Nam – đứng ở đâu?
Phần lớn cuộc tranh luận về đạo đức AI hiện nay đến từ phương Tây – nơi các đại học, think tank và viện nghiên cứu đã bắt đầu lên tiếng. Trong khi đó, các quốc gia như Việt Nam lại đang bị cuốn vào dòng xoáy nhập khẩu công nghệ, từ phần mềm xử lý hình ảnh đến công cụ học máy, mà không kèm theo bộ giá trị bản địa.
Việc dùng AI để chấm thi, giám sát giao thông, thẩm định nhân sự, phân tích tài chính… đang diễn ra từng ngày tại Việt Nam – nhưng chưa có bộ quy chuẩn đạo đức, chưa có luật bắt buộc kiểm toán thuật toán, và chưa có cơ chế bảo vệ công dân nếu bị sai sót.
Chúng ta đang đi vào một thời đại mà AI được “thuê ngoài” từ nước khác, dữ liệu công dân lại nằm trên nền tảng ngoại, còn hệ giá trị đạo đức thì vẫn chưa được xây dựng nội sinh. Điều đó không chỉ gây nguy cơ lệ thuộc – mà còn đe dọa bản sắc và quyền định đoạt của xã hội Việt Nam trong chính tiến trình số hóa của mình.
IV. Chủ quyền dữ liệu và tương lai tự quyết số của Việt Nam
4.1. Dữ liệu công dân đang chảy đi đâu?
Trong thế giới phẳng số hóa, biên giới quốc gia không còn là những vạch kẻ trên bản đồ, mà là những luồng dữ liệu vô hình. Và đáng tiếc, Việt Nam – cũng như nhiều nước đang phát triển – vẫn chưa kiểm soát được dòng chảy ấy.
Mỗi khi người Việt dùng Google để tìm kiếm, gửi tin nhắn qua Facebook Messenger, lưu trữ ảnh lên iCloud, quẹt TikTok… dữ liệu hành vi, sinh trắc, vị trí, thói quen, lịch sử tương tác – đều được gửi tới các máy chủ ở Mỹ, Trung Quốc, Singapore hoặc Ireland.
Điều đáng nói là: dữ liệu này không dừng lại ở đó. Nó được dùng để huấn luyện AI, để xây dựng hồ sơ hành vi tiêu dùng, để tinh chỉnh thuật toán phân phối quảng cáo, và thậm chí để hỗ trợ các mô hình AI thế hệ mới.
Chúng ta đang ở trong một tình thế ngược đời:
- Công dân nộp dữ liệu miễn phí cho các tập đoàn nước ngoài.
- Các tập đoàn kiếm lợi từ AI huấn luyện bằng dữ liệu ấy.
- Rồi quay lại bán sản phẩm AI (dịch vụ, phần mềm, công cụ) với giá cao cho chính quốc gia nơi dữ liệu phát sinh.
Việt Nam xuất khẩu “vàng mềm” – mà không hề biết.
Đó là chủ quyền bị khoét mòn từ bên trong, không tiếng súng, không hiệp ước.
Thực trạng này không còn là nguy cơ, mà là một dạng lệ thuộc công nghệ dạng mới, được ngụy trang trong ngôn ngữ của tiện lợi và miễn phí.
4.2. AI Việt cần bản sắc riêng: Không thể chỉ đi thuê trí tuệ ngoại quốc
Việt Nam đang đối mặt với một câu hỏi sống còn trong thế kỷ 21:
Chúng ta sẽ trở thành quốc gia sản xuất trí tuệ – hay chỉ là nơi cung ứng dữ liệu thô cho người khác luyện trí tuệ của họ?
📌 Một nghịch lý đang diễn ra
Trên thực tế, hàng triệu lượt tìm kiếm, lướt mạng, tương tác bằng tiếng Việt mỗi ngày đều trở thành “dữ liệu ngữ nghĩa” quý giá – nuôi sống các mô hình AI nước ngoài như Google Gemini, Meta LLaMA, OpenAI GPT, ByteDance… Nhưng khi người Việt cần công cụ AI phục vụ chính mình – từ chatbot chăm sóc khách hàng, trợ lý giáo dục, tổng hợp văn bản hành chính – chúng ta lại quay sang nhập khẩu chính những công nghệ đã ăn dữ liệu Việt để lớn lên.
Đây là một hình thức chảy máu chất xám ngược. Không cần di cư nhân lực – chỉ cần người Việt tiếp tục sử dụng nền tảng ngoại với tần suất cao, chất xám sẽ bị trích xuất tự động qua mỗi lượt tương tác. Và điều nguy hiểm là: không ai thấy máu.
📌 Bản địa hóa AI không chỉ là ngôn ngữ – mà là tầm nhìn
Một mô hình AI bản địa không chỉ hiểu tiếng Việt – mà phải hiểu cả bối cảnh văn hóa, hành vi xã hội, và hệ giá trị riêng biệt của dân tộc này.
- Trong văn hóa Việt, “im lặng” có thể là đồng thuận, phản đối, hoặc từ chối lịch sự. AI không hiểu ngữ cảnh sẽ phản ứng sai.
- Trong môi trường học đường, một lỗi sai đạo đức nhỏ có thể dẫn tới “phản cảm văn hóa” – nhưng AI ngoại không có bộ tiêu chuẩn tương thích để đánh giá điều này.
- Trong hành chính công, những hệ thống chatbot hoặc phân loại tự động được thuê từ công ty nước ngoài có thể tạo ra thiên lệch trong việc tiếp cận dịch vụ, vì AI không hiểu sự khác biệt giữa người Kinh – người Mường – người Khmer – người H’Mông.
Nếu AI không được dạy để hiểu người Việt, nó sẽ phản ánh một mô hình văn hóa khác – thường là của Mỹ, Trung Quốc, hay phương Tây. Điều này nguy hiểm ở tầm chính trị và xã hội, vì:
“Người kể chuyện sẽ là kẻ thống trị tương lai.” – Yuval Noah Harari
Nhưng kẻ tạo ra AI – chính là người viết lại cách chúng ta kể chuyện với nhau.

📌 Tầm nhìn không thể thuê: Trí tuệ phải là nội lực quốc gia
Trong các nền văn minh lớn, AI không được xem là công cụ kinh doanh đơn thuần – mà là biểu tượng quyền lực quốc gia. Trung Quốc có chiến lược “China Standards 2035” – trong đó AI là xương sống kiến thiết một hệ sinh thái tiêu chuẩn riêng cho thế giới nói tiếng Hoa. Mỹ có chiến lược AI quốc gia với đầu tư hàng chục tỷ USD/năm, gắn AI với quân sự, ngoại giao, và năng lực cạnh tranh toàn cầu. Ấn Độ lập trình “AI for All,” phát triển các mô hình AI bằng tiếng Hindi và hơn 20 ngôn ngữ địa phương.
Việt Nam – nếu muốn giữ vai trò chủ động trong thời đại mới – cần đi theo một hướng tự xây nền móng AI dựa trên:
- Ngữ liệu tiếng Việt sạch, phong phú, có gắn ngữ cảnh văn hóa.
- Đội ngũ AI ethics, AI policy bản địa – không vay mượn hệ chuẩn phương Tây hay Trung Hoa.
- Chính sách bảo hộ dữ liệu công dân, ngăn chặn trích xuất phi pháp thông tin nhạy cảm ra khỏi lãnh thổ số.
- Hệ sinh thái AI ứng dụng cho giáo dục, hành chính công, truyền thông văn hóa Việt.
Không một quốc gia nào có thể phát triển bền vững khi trí tuệ của chính mình được gói trong thuật toán của kẻ khác. AI bản địa là nền móng để Việt Nam không chỉ số hóa – mà tự do hóa trí tuệ dân tộc.
V. Kiến tạo hệ giá trị số: Từ phản kháng đến chủ động định hình
Sau khi bóc tách các lỗ hổng đạo đức, các vụ thao túng chính trị và nguy cơ lệ thuộc dữ liệu, điều quan trọng nhất không còn là phản ứng lo lắng, mà là xây dựng một hệ giá trị chủ động. Một tầm nhìn dài hạn về AI và dữ liệu ở Việt Nam không thể chỉ là chiến lược công nghệ – mà phải là chiến lược văn hóa, giáo dục, và chính trị.
5.1. Ba trụ cột cần thiết: Tri thức – Chính sách – Cộng đồng công nghệ
1. Tri thức: Hệ sinh thái giáo dục thuật toán và tư duy số
Việt Nam cần kiến tạo một chương trình giáo dục AI – đạo đức – dữ liệu ngay từ cấp trung học. Không thể để người trẻ sử dụng công cụ mà không hiểu logic phía sau, hoặc trở thành nạn nhân của hệ thống mà không đủ ngôn ngữ để chất vấn.
- Dạy AI không chỉ là học code – mà là học cách đặt câu hỏi đúng, hiểu cơ chế ra quyết định, và nhận diện thiên kiến ngầm.
- Môn “Đạo đức Dữ liệu” (Data Ethics) nên trở thành trụ cột mới của giáo dục công dân trong kỷ nguyên số.
2. Chính sách: Chủ quyền dữ liệu phải là nền tảng an ninh quốc gia
Cần có luật dữ liệu cá nhân mạnh mẽ, không chỉ sao chép từ GDPR hay mô hình Trung Quốc.
Chủ quyền số của Việt Nam phải đặt trên ba nguyên tắc:
- Dữ liệu cá nhân là tài sản có quyền sở hữu.
- Mọi AI sử dụng dữ liệu Việt phải có trách nhiệm giải trình và tuân thủ khung đạo đức Việt.
- Phải có cơ chế kiểm toán độc lập cho các hệ thống AI triển khai trong lĩnh vực công.
Việt Nam cần một Hội đồng đạo đức AI cấp quốc gia, quy tụ các chuyên gia đa lĩnh vực – từ công nghệ đến triết học, luật học và nhân học.
3. Cộng đồng công nghệ: Đổi từ tiêu thụ sang kiến tạo
Phần lớn người Việt hiện vẫn là người tiêu thụ AI: dùng ChatGPT để viết văn, dùng Midjourney để vẽ tranh, dùng các app để chỉnh ảnh và dịch thuật.
Nếu không có cộng đồng nhà phát triển AI người Việt bản địa, ta sẽ vĩnh viễn ở thế yếu.
- Cần quỹ đầu tư mạo hiểm chuyên biệt cho startup AI Việt.
- Các đại học cần mở rộng liên kết với viện nghiên cứu, doanh nghiệp để tạo sản phẩm thực tế.
- Đặc biệt, cần tạo hệ sinh thái AI tiếng Việt có chất lượng – từ dữ liệu ngữ nghĩa, thư viện nguồn mở, đến nền tảng thử nghiệm mô hình.
Đừng đợi có “AI Việt đầu tiên” từ một gã khổng lồ công nghệ. Hãy kiến tạo nó từ những nhóm nhỏ, có tầm nhìn và được nuôi dưỡng bởi tri thức bản địa.
5.2. Trách nhiệm và cơ hội của người Việt trẻ
Nếu người trẻ chỉ dùng AI để lách bài tập, làm content nhanh hay chạy quảng cáo tốt hơn… thì dù công nghệ mạnh đến đâu, người Việt vẫn ở đáy chuỗi giá trị.
Trách nhiệm của thế hệ trẻ – nhất là những người có tri thức – không nằm ở việc chạy theo công cụ mới nhất, mà ở chỗ biết chất vấn, biết chọn lọc, và biết xây dựng nền tảng trí tuệ lâu dài.
- Học kỹ về ngôn ngữ của thuật toán, để không bị nó dẫn dắt mù quáng.
- Nhận diện khi nào một AI phản ánh thiên kiến, và biết can thiệp vào thiết kế của nó.
- Dám xây mô hình riêng, dù nhỏ – vì AI không cần khổng lồ để tạo tác động, chỉ cần đúng cộng đồng.
Trong kỷ nguyên AI, chậm không đáng sợ bằng không hiểu. Và hiểu thôi cũng chưa đủ – phải dám cài lại hệ điều hành tư duy của chính mình.
VI. Kết luận: Kỷ nguyên AI cần một bản đồ đạo đức và chiến lược Việt
Trí tuệ nhân tạo và dữ liệu lớn đang định hình lại thế giới – không phải ở cấp độ công nghệ, mà ở cấp độ quyền lực, nhận thức và đạo đức. Chúng ta đang sống trong một thời đại mà mỗi lượt tìm kiếm, mỗi dòng chữ, mỗi cú click – đều có thể trở thành nguyên liệu cho một hệ thống AI nào đó học, phán đoán, và hành động thay ta.
Nếu không có chiến lược riêng, Việt Nam sẽ tiếp tục là nơi cung cấp dữ liệu – nhưng không bao giờ sở hữu tri thức. Nếu không có đạo đức riêng, AI sẽ trở thành người kể chuyện sai về chính chúng ta. Và nếu không có cộng đồng bản địa sáng tạo, năng lực số sẽ mãi nằm trong tay kẻ khác.

Nhưng cơ hội vẫn còn – và cánh cửa chưa khép lại. Trong thế giới mà mọi thứ đều có thể bị sao chép, duy chỉ có bản sắc – và tầm nhìn dài hạn – là không thể làm giả. Việt Nam có thể, và cần, kiến tạo một bản đồ đạo đức – chiến lược – giáo dục – công nghệ cho riêng mình, nơi AI không chỉ phục vụ phát triển, mà còn bảo vệ linh hồn văn hóa dân tộc.
Tương lai không tự đến. Nó được lập trình.
Và người Việt – nếu không lập trình lấy tương lai mình – sẽ bị lập trình bởi kẻ khác.
Bạn muốn đồng hành cùng chúng tôi trên hành trình này?
👉 Hãy đăng ký theo dõi Vietfuturus.org để nhận loạt bài chiến lược tiếp theo về AI, dữ liệu, công nghệ và bản sắc số Việt.
Chúng ta không chống lại AI – nhưng nhất định không để nó thay ta nghĩ.
📚 Nguồn & Tài liệu tham khảo
- Cadwalladr, C., & Graham-Harrison, E. (2018). The Cambridge Analytica Files. The Guardian.
- Harari, Y. N. (2018). 21 Lessons for the 21st Century.
- Crawford, K. (2021). Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence. Yale University Press.
- UNESCO (2021). Recommendation on the Ethics of Artificial Intelligence.
- Brookings Institution (2023). AI Governance and the Global South: Risks and Pathways.
- Vietnam Digital Transformation Strategy to 2025, vision to 2030 – Bộ Thông tin & Truyền thông.



One Comment